project
11
Last Updated:
NYU Machine Learning Project
Improving object detection in surveillance footage using ESRGAN Image Upscaling and Inception ResNet v2
Collaborators

The Tech Stack
- Python
- NumPy
- Pandas
- Google Colab
- Jupyter Notebooks
All Hail Big Brother
What better way to utilize machine learning algorithms than to use them to enact swift justice in the most privacy-violating way possible? Not really, I don't support a mass-surveillance state. However, in the last-minute crunching days of finals week we had to come up with a creative project that showcased most of what we learned during the course. Something that was relatively simple to get off the ground without requiring weeks of training models.
Brainstorming
In the Piazza course section we were a part of, we heard it all. Students were planning to use ML models to predict food spoilage from photos, try to create language prediction models and more. We wanted to try our hand at something different, something applied and a little out of scope. After a few back and forth brainstorming sessions, we decided to try applying machine learning on surveillance footage. Typical surveillance footage is usually of low resolution to ensure it can be stored for a long time in a storage conscious way. Not every organization has the funds to allow 120 frames-per-second, 4K resolution video recording, 24/7, 365 days a year. So most solutions often revolve around using compression, lower resolution capture and even periodic captures every few minutes to decrease the size of the file. It all depends on the client's needs. We figured we could improve upon this shortcoming with ML. Our hypothesis was that we assumed we could take existing surveillance footage, upscale it to a higher resolution, perform object detection on those higher quality images and be able to detect more objects and with higher confidence scores than the original, low-quality footage. This was by no means an original idea (even our grading TA gave us a B+ for creativity), but at the time we didn't find any papers directly merging the two. Maybe we didn't look hard enough. Still, the project terms were not about originality, but execution. (We're certain governments across the world already implemented such systems, whether they want to admit it or not, at scales and with features we cannot even fathom.)
Mental Walkthrough of the Process
There are many ways to validate the efficacy of a machine learning model: the number of correctly labeled pieces of data, the quality of a supersampled picture, correctly predicting letters in a hand-written note, etc. We needed some quantitative value to merit the success of our model. We decided to use the object detection aspect as both a secondary challenge for us and a metric for evaluating our hypothesis; the scores we needed that told us whether we succeeded or failed in our goal.
Our approach originally had promise, and by the time we got up to the point of upscaling footage and running detection models over it, we were too close to the deadline to back out. Below is output from our Colab notebook applying our process on a real surveillance image.
 Object detection scores over the original surveillance footage (left) Object detection scores over the ESRGAN Enhanced footage (right) Due to the resolution enhancement of ESRGAN, the output text and bounding boxes created in the python program are scaled proportionally, leading to difficulty reading. Thus, for added readability, I duplicated the output detection scores here.
Object detection scores over the original surveillance footage (left) Object detection scores over the ESRGAN Enhanced footage (right) Due to the resolution enhancement of ESRGAN, the output text and bounding boxes created in the python program are scaled proportionally, leading to difficulty reading. Thus, for added readability, I duplicated the output detection scores here.
We saw instantly that confidence ratings in the upscaled images rose across the board. In this cherry-picked image alone, we saw ratings going up. This was one of our first tests, so we were stoked.
It All Goes Wrong
So, you might be thinking to yourself, higher resolution photos coupled with object detection means higher rates of detection, common sense, right? Not quite, at least that's not what came out of our project. In some instances, object detection went up by near 30%, in other instances, such as when applying our workflow to surveillance videos, our detection plummeted.
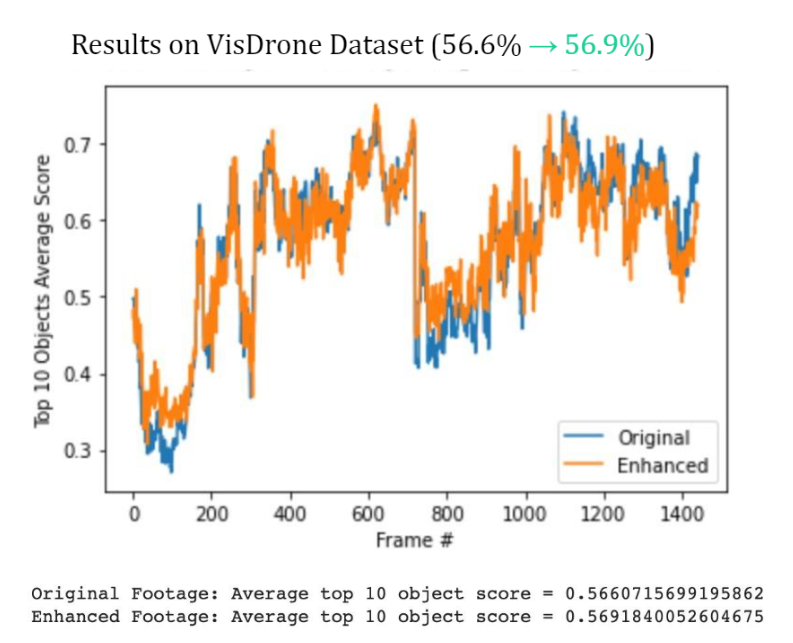
Taking over 1400 images from the VisDrone dataset, we reached a marginal increase in detection confidence scores, from 56.6% to 56.9%, hardly something to pop bottles over.


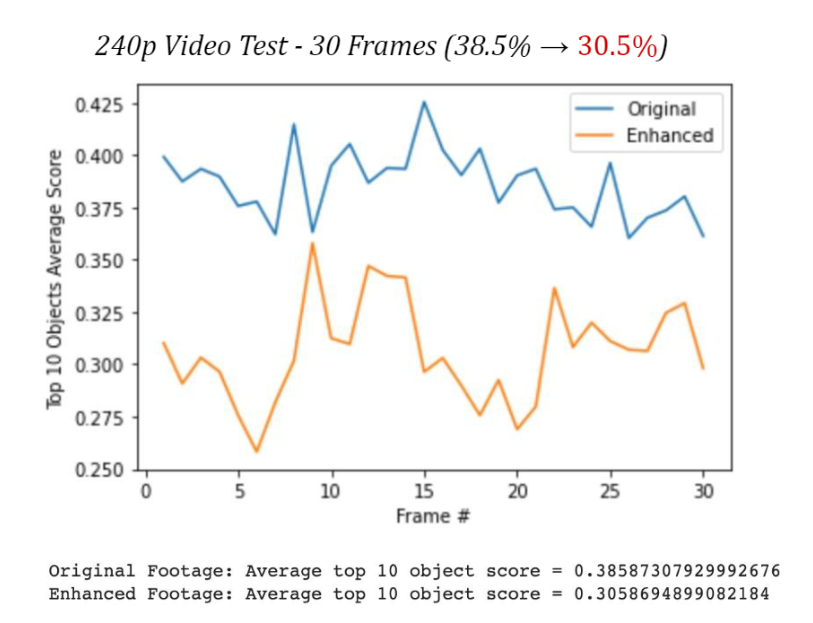
When it came to running this model over a 240p dashcam video, the results completely bombed, dropping from an average confidence of 38.5% to 30.5%, painful to say the least.
All Hope is Not Lost
We have a few theories as to why that might have been. The first elephant in the room was that the object detection model we were using was re-trained on a very limited dataset, not enough to properly tweak all the parameters for solid detection. (We did briefly attempt to retrain the detection model on our upscaled images to improve scores, however even with Google Colab's GPU support, we needed over 11 days to train it. Something we did not have at the time.)
The second issue was something we noticed only after getting well into the project. ESRGAN, while doing a fantastic job of trying to increase the resolution of low quality images, also resulted in some expected artifacts in the images.
 Originall surveillance footage (left) ESRGAN enhananced image (right) Noticable artifacts are appear in the enhanced image, particularly around the tires of the gray car and around various details of the white cars.
Originall surveillance footage (left) ESRGAN enhananced image (right) Noticable artifacts are appear in the enhanced image, particularly around the tires of the gray car and around various details of the white cars.
 Close-up of the ESRGAN enhanced image
Close-up of the ESRGAN enhanced image
These artifacts, while not mission critical to the human eye, are significant enough to most likely confuse object detection models trained on normal images. This could all be fixed most certainly given enough time and training of object detection models on super-resolutioned images.
In closing, this was meant to be a fun, end-of-semester, project allowing us to flex our muscles on all that we have learned throughout the course. We did go a bit above and beyond in our scope, but we learned a lot about how real-world model training and evaluation is done. Sure, the raw results aren't great, but we were happy enough to know the damn idea worked and that we actually were able to pull this off. We are certain that given enough training data, computing time, resources and caffeine, this could actually be implemented in the real world with much higher rates of success than we achieved here. However, we leave that to other teams and curious students to tackle and leave this work squarely as just another project for a university course.
How was this article?
If you want to send me specific feedback, please do so on the Contact Page. Thank you!